Dla kogo:
Problem:
Narzędzia produktywności miały ułatwiać pracę, ale skończyło się na tym, że sama ich obsługa stała się pracą. Informacja o kliencie jest w arkuszu, ustalenia ze spotkania w notatkach, korespondencja w mailu, a brief w PDF na dysku. Żeby odpowiedzieć na proste pytanie "co ustaliliśmy z tym klientem i jaki ma budżet" trzeba otworzyć trzy aplikacje. Gotowe asystenty typu ChatGPT czy Gemini nie znają tego kontekstu, bo nie mają dostępu do Twoich danych.
Rozwiązanie:
Asystent AI na Telegramie zbudowany na własnej infrastrukturze, który ma dostęp do Twoich dokumentów, maili, kalendarza i bazy klientów. Działa dwutorowo: proste, powtarzalne akcje wykonują dedykowane, deterministyczne ścieżki uruchamiane komendami, a złożone zadania wymagające myślenia trafiają do agenta AI z pamięcią i własną bazą wiedzy.
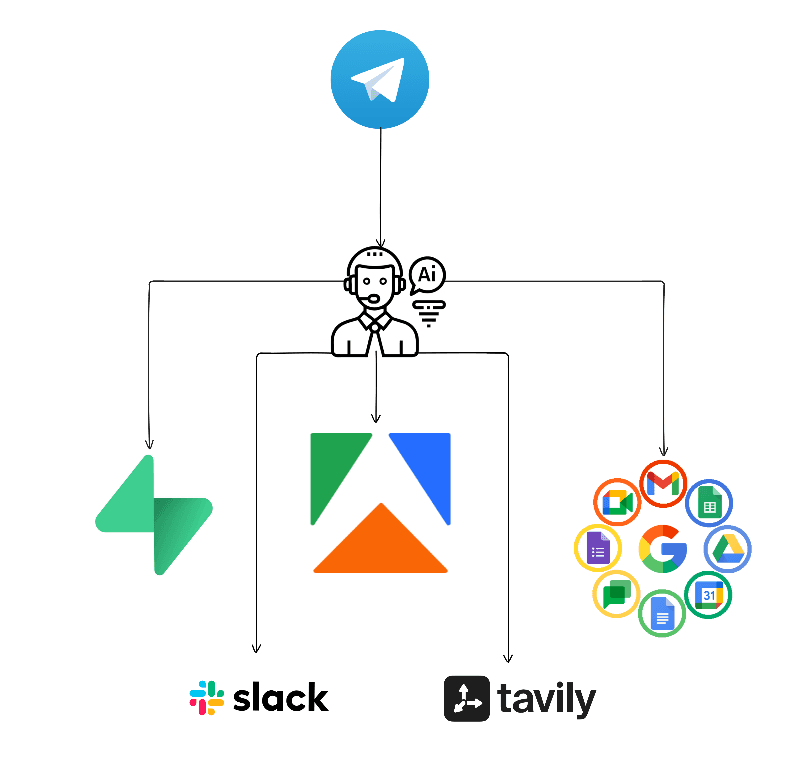
Architektura, czyli najważniejsza decyzja projektowa:
Świadomie nie zbudowałem jednego wszechmocnego agenta, który robi wszystko. Zamiast tego wiadomości przechodzą przez router, który rozdziela je na ścieżki. Akcje deterministyczne (wgranie pliku, zapis notatki, scrapowanie linku) nie przechodzą przez AI, tylko przez osobne, przewidywalne ścieżki. Dzięki temu nie ma ryzyka, że model coś zmyśli czy pomyli, a system jest banalnie prosty w rozbudowie: dodanie nowej funkcji to dorzucenie kolejnej gałęzi, bez ruszania reszty i bez przepisywania promptu agenta.
Jak działa, komendy:
/sl wysyła wiadomość bezpośrednio na Slacka, z automatycznym rozróżnieniem czy idzie na kanał czy jako prywatna wiadomość do konkretnej osoby.
/d wgrywa załączony plik na Google Drive, z mapowaniem do odpowiedniego folderu (Briefy, Raporty, Misc).
/v wgrywa dokument do wektorowej bazy danych, dzięki czemu agent może potem korzystać z jego treści.
/m zapisuje krótką notatkę tekstową do bazy wiedzy, na przykład "klient z budżetem 5000 zł to klient rangi premium".
/s scrapuje podany link (przez Apify dla mediów społecznościowych, przez czytnik tekstu dla zwykłych stron) i zapisuje treść do Google Docs.
Wiadomość bez komendy trafia do agenta AI.
Agent AI:
Sercem systemu jest agent z pamięcią ostatnich kilkunastu wiadomości (PostgreSQL) i dostępem do wektorowej bazy wiedzy (Supabase). Potrafi: przeszukiwać wgrane dokumenty znaczeniowo (nie po słowach kluczowych, ale po sensie), odczytywać i przeszukiwać arkusze klientów, pisać i wysyłać maile po potwierdzeniu, sprawdzać i tworzyć wydarzenia w kalendarzu, robić research w internecie przez Tavily, tworzyć dokumenty w Google Docs i odsyłać wyniki z powrotem na Telegram. Agent ma jasno zdefiniowane ograniczenia: nie wysyła maili bez zgody, nie usuwa danych, nie edytuje istniejących plików (tworzy nowe), a przy niejasnych poleceniach dopytuje zamiast zgadywać.
Dwa rodzaje pamięci:
Projekt świadomie rozdziela dwa typy danych. Dane strukturyzowane (klienci, budżety, statusy) żyją w arkuszach, gdzie liczy się dokładne dopasowanie. Dane niestrukturyzowane (briefy, notatki, strategie) trafiają do wektorowej bazy, gdzie agent szuka po znaczeniu. Dzięki temu na pytanie "co wiemy o strategii klienta" agent znajdzie właściwy fragment, nawet jeśli nie padło w nim ani jedno słowo z zapytania.
Stack:
n8n, Telegram, OpenAI (model agenta + embeddingi text-embedding-3-small), Supabase (wektorowa baza danych z pgvector), PostgreSQL (pamięć konwersacji), Gmail, Google Calendar, Google Sheets, Google Docs, Google Drive, Slack, Tavily, Apify.
Możliwe rozbudowy:
Architektura oparta o router sprawia, że dodanie nowej funkcji jest trywialne. Naturalne kolejne kroki to: poranny briefing wysyłany automatycznie (kalendarz na dziś plus pilne maile), kategoryzacja przychodzącej poczty, oraz przypomnienia z kontekstem przed spotkaniami. Te funkcje wymagają osobnych workflow z wyzwalaczem czasowym, ale korzystają z tej samej bazy wiedzy.





